


 Yeni Kayıt
Yeni Kayıt










 Konudaki Resimler
Konudaki Resimler

 önceki
önceki
< Bu mesaj bu kişi tarafından değiştirildi Tugrul_512bit -- 30 Nisan 2013; 17:25:42 > |
 tabi paylaşmak istersen. Oyun grafik motoru olarak sadece jmonkey engine kullandım ve şu anda unity öğreniyorum.
tabi paylaşmak istersen. Oyun grafik motoru olarak sadece jmonkey engine kullandım ve şu anda unity öğreniyorum.  zamanında cpu için yazdığımda bir sürü özelliği vardı depth of field, aa, soft shadows, reflection, refraction, texture vs vs... 5500 satır civarında ve çok fazla tekrar comment out içeriyor şu anki versiyonu
zamanında cpu için yazdığımda bir sürü özelliği vardı depth of field, aa, soft shadows, reflection, refraction, texture vs vs... 5500 satır civarında ve çok fazla tekrar comment out içeriyor şu anki versiyonu  kodu temizlediğim zaman atayım sana güzel olur opencl versiyonu.
kodu temizlediğim zaman atayım sana güzel olur opencl versiyonu. 









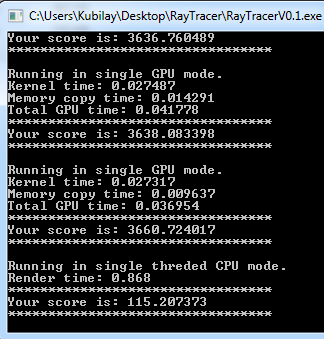
 hafta sonu almıştım o skoru
hafta sonu almıştım o skoru
 bende bir sorun cıktı heralde dedim neyse sevimdim bir sorun olmadıgına kaan hocam tekrar hayırlı olsun
bende bir sorun cıktı heralde dedim neyse sevimdim bir sorun olmadıgına kaan hocam tekrar hayırlı olsun





















Bildirim





< Bu mesaj bu kişi tarafından değiştirildi Tugrul_512bit -- 30 Nisan 2013; 17:25:42 > |
|
|
< Bu mesaj bu kişi tarafından değiştirildi hanibal187 -- 30 Nisan 2013; 17:53:34 > |
< Bu mesaj bu kişi tarafından değiştirildi Tugrul_512bit -- 30 Nisan 2013; 18:05:16 > |
|
|
< Bu mesaj bu kişi tarafından değiştirildi arbiter -- 30 Nisan 2013; 20:40:09 > |
|
|
|
|
|
|
< Bu ileti mobil sürüm kullanılarak atıldı > |
|
|
|

