


 Yeni Kayıt
Yeni Kayıt










 Konudaki Resimler
Konudaki Resimler
|

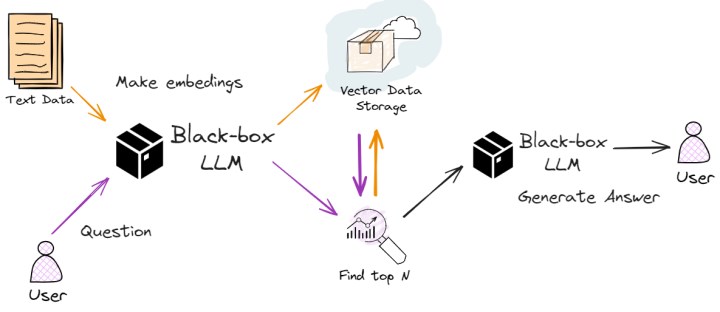






















Bildirim





|
Harbiden aydınlatıcı bi makale olmuş çabalarınızdan dolayı teşekkür ederim
|
|
Mükemmel bir makale, editörümüzün emeğine sağlık, Metin Yasir Akpınar gerçekten çok değerli bir kalem. Geçenlerde Google Gemini kullanırken geçmişimizi kapatmazsak, kaydedilen verilerimizi daha sonradan silsek dahi 3 yıl kalacağını öğrenince, aklım gitmişti. Silinmediğini kamuoyu bilsin diye Sn. Akpınar'a yazdığımda aslında problemin hiç de basit olmadığını ifade etmişti. Evet mesele kayıt silmek değil çünkü ortada bizim bildiğimiz algıladığımız boyutta söz gelimi bir veritabanı yok. Bu makalede de genişçe yer ayrıldığı gibi LLM'lerin çalışma sistemi bambaşka. Gizlilik açısından alınabilecek tek önlem firmaların dürüst bir şekilde verilerinizin eğitimde kullanılmasın isteğinize uyması kalıyor: ChatGPT'te bununla ilgili bir seçenek var (eskiden yoktu sanırım gelmiş). Google Gemini ise sadece geçmiş kapatılırsa bunu sağlayacağını söylüyor (gibi anladım). Elbette bunlar firmaların taahhütleri. Kasıtlı olarak dürüst olmayabilirler. İleride bilmem kaç yüz milyar dolar cezayı da göze almışlar olabilirler. Çünkü 2 durum var: 1) RLHF ihtiyacı: Bu makalede yer verildiği gibi; esasen işin özünde kişisel verilerimizden öte RLHF gibi teknik gereksinimler var. Bunu da ancak biz organik kullanıcılar sağlayabiliriz. Bu bir yere kadar kabul edilebilir durum. Sonuçta insanlığın yapay zekadaki büyük gelişimi için bu küçük adımlara ihtiyaç var ve bu bağlamda zafere giden her yol mübahtır. 2) Şeytani plan: Bu da birinci maddeyle birlikte olabilecek bir ihtimal. Gayet mümkün bir komplo. Öyle ki yapay zekayla oluşan samimi ortamda hiç açıklanmaması ve sır saklanması gereken meseleler açığa çıkıyor. Yine bu sayede profilleme yapılabilir. Nasıl nerede kullanılacağının ucu bucağı yok. Bilginin güç olduğunu biliyoruz. Bu kadar bilgiyle hiç savaş çıkarmadan tüm dünyayı ele geçirir, parmağında oynatabilirsin. Kısaca konu cidden basit değil. Haberin böyle verilmesi yerinde olmuş. |
< Bu ileti iOS uygulamasından atıldı > |
|
Mükemmel bir makale, editörümüzün emeğine sağlık, Metin Yasir Akpınar gerçekten çok değerli bir kalem. Geçenlerde Google Gemini kullanırken geçmişimizi kapatmazsak, kaydedilen verilerimizi daha sonradan silsek dahi 3 yıl kalacağını öğrenince, aklım gitmişti. Silinmediğini kamuoyu bilsin diye Sn. Akpınar'a yazdığımda aslında problemin hiç de basit olmadığını ifade etmişti. Evet mesele kayıt silmek değil çünkü ortada bizim bildiğimiz algıladığımız boyutta söz gelimi bir veritabanı yok. Bu makalede de genişçe yer ayrıldığı gibi LLM'lerin çalışma sistemi bambaşka. Gizlilik açısından alınabilecek tek önlem firmaların dürüst bir şekilde verilerinizin eğitimde kullanılmasın isteğinize uyması kalıyor: ChatGPT'te bununla ilgili bir seçenek var (eskiden yoktu sanırım gelmiş). Google Gemini ise sadece geçmiş kapatılırsa bunu sağlayacağını söylüyor (gibi anladım). Elbette bunlar firmaların taahhütleri. Kasıtlı olarak dürüst olmayabilirler. İleride bilmem kaç yüz milyar dolar cezayı da göze almışlar olabilirler. Çünkü 2 durum var: 1) RLHF ihtiyacı: Bu makalede yer verildiği gibi; esasen işin özünde kişisel verilerimizden öte RLHF gibi teknik gereksinimler var. Bunu da ancak biz organik kullanıcılar sağlayabiliriz. Bu bir yere kadar kabul edilebilir durum. Sonuçta insanlığın yapay zekadaki büyük gelişimi için bu küçük adımlara ihtiyaç var ve bu bağlamda zafere giden her yol mübahtır. 2) Şeytani plan: Bu da birinci maddeyle birlikte olabilecek bir ihtimal. Gayet mümkün bir komplo. Öyle ki yapay zekayla oluşan samimi ortamda hiç açıklanmaması ve sır saklanması gereken meseleler açığa çıkıyor. Yine bu sayede profilleme yapılabilir. Nasıl nerede kullanılacağının ucu bucağı yok. Bilginin güç olduğunu biliyoruz. Bu kadar bilgiyle hiç savaş çıkarmadan tüm dünyayı ele geçirir, parmağında oynatabilirsin. Kısaca konu cidden basit değil. Haberin böyle verilmesi yerinde olmuş. < Bu mesaj bu kişi tarafından değiştirildi E_Y_B_H_P_T -- 11 Haziran 2024; 2:34:59 > |
|
Kaliteli bir makale olmuş. Teşekkür ediyoruz. Mesajım bulunsun. |
|
Grafik tasarımdan cok anlamam biraz anlarım fakat ileri seviye bilmem o yüzden gecenlerde yardıma ihtiyacım oldugunda, ChatGPT 4'e adobe illustrator ile ilgili bir soru sordum olmayan menuleri kafasından uyduruyor.. Fakat güzel pazarladılar gercekten sırf pazarlamayla olmayan seyi yani yapay zeka, varmıs gibi sattılar ve satmaya devam ediyorlar.. < Bu mesaj bu kişi tarafından değiştirildi Headlong Into Carnage -- 10 Haziran 2024; 8:34:17 > |
|
Yapay Zekanın ne kadar gelişebileceği konusunda yıllardan beri sinema sektörü gözümüze sokuyor zaten. Şu anda da ne kadar haklı olduklarını görebiliyoruz. |
|
Kaliteli bir başlık, neredeyse tüm sorularıma cevap niteliğinde . |
< Bu ileti mini sürüm kullanılarak atıldı > |
|
Yazı gayet leziz olmuş. Yazı çok uzun olduğu için bunu sonra okurum diyerekten açık sekmede 3 gündür bekletiyordum şimdi okumaya kısmet oldu. Buna değdi de. İlk defa bir haber editörünün yazısında bir forum üyesine -üyeyi birçok yorumundan tanıyorum- referans yapıldığını görüyorum sanırım. Sanırım diyorum, hafızam bulanık olduğundan sanki yıllar evvel bir keresinde daha başka bir haberde görmüş gibiyim ama kimdi, haber neydi hiç hatırlamıyorum neyse. Böyle faydalı içeriklerin devam etmesi dileğiyle. < Bu ileti mobil sürüm kullanılarak atıldı > |

